בשנה האחרונה אני מוצא את עצמי משתמש פחות ופחות במילה SEO, לא כי היא נעלמה, אלא כי היא כבר לא מספיקה.
המעבר מחיפוש שמציג קישורים לחיפוש שמייצר תשובות יצר שכבה חדשה של מושגים, מדדים ושיטות עבודה. פתאום לא מספיק להבין דירוגים וטראפיק. צריך להבין איך מודלי הבינה המלאכותית קוראים תוכן, איך הם בוחרים מקורות, ואיך מותג הופך לחלק מתשובה מסונתזת.
המונחים שנולדו סביב GEO ו – AI Search לא תמיד אינטואיטיביים. חלקם טכניים, חלקם אסטרטגיים, וחלקם פשוט משקפים שינוי תפיסתי שעיקרו תחרות על ייצוג ולא על קליקים.
אבל לפני שמדברים על טקטיקות, חשוב להבין את השפה. בדיוק בשביל זה הכנתי מילון של 50 מושגי יסוד שמגדירים את התחום כיום ומסודרים לפי אסטרטגיה, תשתית, מדידה וסמכות דיגיטלית.
כי בעולם שבו תשובות נכתבות על ידי AI, מי שלא מבין את המונחים נשאר מחוץ לנרטיב.
פרק א’: אסטרטגיות אופטימיזציה ודיסציפלינות ליבה
1. GEO (Generative Engine Optimization)
אופטימיזציה למנועי חיפוש ג’נרטיביים היא הפרקטיקה המקצועית של התאמת תוכן דיגיטלי כך שיופיע כמקור מצוטט, מיוצג ומעובד בתגובות המיוצרות על ידי מערכות בינה מלאכותית יוצרת. בניגוד לשיטות המסורתיות, ה-GEO מתמקד בשיפור הנראות בתוך נרטיבים מסונתזים של מודלים כמו ChatGPT, Claude ו-Perplexity, תוך שימוש בטכניקות של העשרת עובדות ושיפור קריאות המכונה.
2. AEO (Answer Engine Optimization)
אופטימיזציה למנועי תשובות היא תחום המתמקד ביצירת תוכן המספק מענה ישיר, תמציתי ומדויק לשאלות משתמשים, במטרה להופיע בתוצאות ה”אפס קליקים” ובתיבות התשובה המהירה. טכניקה זו מקדימה את ה-GEO הכרונולוגי ומהווה בסיס קריטי להבנת הדרכים בהן מערכות AI שולפות מידע נקודתי מתוך מאמרים רחבים.
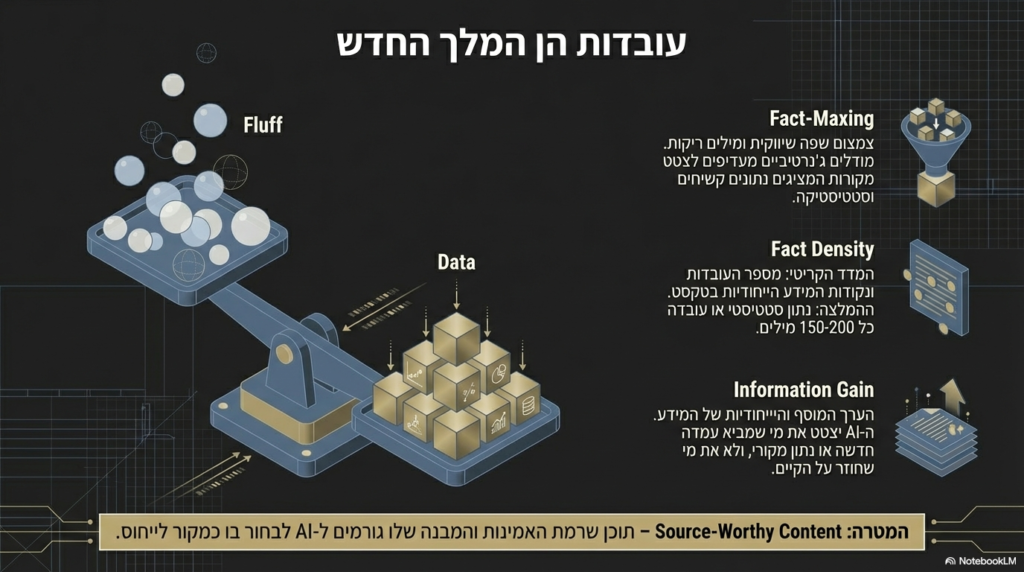
3. Fact-Maxing (מקסימיזציה של עובדות)
אסטרטגיית תוכן המתמקדת בהגברת צפיפות המידע והעובדות המאומתות בטקסט, תוך צמצום משמעותי של שפה שיווקית או מילים ריקות (Fluff) שאינן תורמות לערך האינפורמטיבי. מחקרים מצביעים על כך שמודלים ג’נרטיביים נוטים לצטט מקורות המציגים נתונים קשיחים וסטטיסטיקה בתדירות גבוהה יותר מאשר טקסט נרטיבי רך.
4. Semantic Chunking (קיטוע סמנטי)
תהליך טכני של חלוקת תוכן ליחידות מידע (Chunks) המבוססות על משמעות רעיונית שלמה, ולא על חלוקה שרירותית של פסקאות, כדי להקל על מודלי ה-RAG לאחזר מידע מדויק. קיטוע נכון מבטיח שכל פיסת מידע הנשלפת על ידי המנוע תשמור על ההקשר ההכרחי להבנתה כחלק מהתשובה הכוללת.
5. Content Atomization (אטומיזציית תוכן)
גישה אסטרטגית לפירוק מאמרים מקיפים ליחידות תוכן קטנות, עצמאיות ובעלות ערך פונקציונלי, המאפשרות למודלי ה-AI לצרוך ולסנתז את המידע בקלות רבה יותר. כל “אטום” של מידע צריך להיות מסוגל לעמוד בפני עצמו ולהסביר מושג או להשיב על שאלה ללא תלות ביתר חלקי המאמר.
6. Source-Worthy Content (תוכן ראוי לציטוט)
תוכן המאופיין ברמת אמינות, סמכותיות ומבנה טכני הגורמים למודל הבינה המלאכותית להעדיף אותו כמקור לייחוס (Citation) בתוך התשובה המופקת. זהו רף איכות חדש הדורש לא רק כתיבה טובה, אלא גם הוכחות חיצוניות, קישורים למחקרים ראשוניים ומוניטין של הכותב בתחום המקצועי.
7. Fact Density (צפיפות עובדות)
מדד המגדיר את מספר העובדות, הנתונים הסטטיסטיים או נקודות המידע הייחודיות הקיימות בתוך רצף טקסטואלי נתון, כאשר צפיפות גבוהה מקושרת לסיכויים גבוהים יותר לציטוט ב-AI. ההמלצה המקצועית היא לשלב נתון סטטיסטי או טענה עובדתית מגובה כל 150-200 מילים כדי לשפר את ה-GEO.
8. Authoritative Rewriting (שכתוב סמכותי)
טכניקה הכוללת עריכה מחדש של תכנים קיימים כדי להעניק להם סגנון כתיבה המדמה מקורות אקדמיים או מקצועיים בכירים, תוך שימוש בטרמינולוגיה מדויקת ומבנה היררכי ברור. שכתוב זה נועד להקטין את ה”רעש” עבור המודל ולהבליט את המידע העיקרי שניתן לסנתז.
9. Inverse Pyramid Structure (מבנה פירמידה הפוכה)
שיטת ארגון תוכן שבה המסקנות העיקריות והתשובות הישירות מופיעות בראש הדף או הפסקה, בעוד שהפרטים המשלימים וההקשר הרחב מופיעים בהמשך. מבנה זה מותאם במיוחד לאופן בו מנועי חיפוש ג’נרטיביים סורקים ומאחזרים מידע, שכן הוא מקטין את הנטל הקוגניטיבי על המודל במציאת התשובה.
10. Machine-Legible Content (תוכן קריא למכונה)
סטנדרט הגשה של תוכן המותאם לסריקה על ידי בוטים של AI, הכולל HTML נקי, שימוש נכון בתגיות היררכיות (H1-H4) והימנעות מקוד מורכב מדי המפריע לעיבוד הטקסט. תוכן קריא למכונה מבטיח שהטוקנים המעובדים על ידי המודל יתמקדו בתוכן עצמו ולא במבנה הטכני המקיף אותו.
11. Answer-First Pattern (תבנית “תשובה תחילה”)
טכניקת כתיבה המיועדת להשיב על שאילתת המשתמש באופן מיידי בראש הדף, בדרך כלל בתוך 1-2 משפטים, לפני הרחבה על הנושא. דפוס זה הוכח כיעיל מאוד בהשגת Featured Snippets וציטוטים במנועי תשובות כמו Perplexity וגוגל SGE.
12. Topic Clusters (צבירי נושאים)
שיטה לארגון תוכן האתר סביב נושאי ליבה רחבים המקושרים לתת-נושאים מפורטים, מה שעוזר למנועי חיפוש ולבינה מלאכותית לזהות “סמכות נושאית” (Topical Authority) של דומיין. צבירים אלו יוצרים רשת סמנטית פנימית המקלה על המודל להבין את עומק המומחיות של המותג בתחום מסוים.
פרק ב’: תשתיות טכנולוגיות ומנגנוני LLM
13. LLM (Large Language Model)
מודל שפה רב-פרמטרים שאומן על כמויות אדירות של טקסט כדי להבין ולייצר שפה טבעית, ומהווה את ליבת המנוע של מערכות החיפוש הג’נרטיביות. מודלים אלו פועלים על בסיס חיזוי הסתברותי של רצפי מילים, מה שמחייב אופטימיזציה מבוססת הקשר וסטטיסטיקה.
14. RAG (Retrieval-Augmented Generation)
תהליך שבו מודל הבינה המלאכותית מחזק את יכולותיו באמצעות שליפת מידע עדכני ממקורות חיצוניים בזמן אמת, מה שמאפשר לו לספק תשובות המבוססות על נתונים שלא היו קיימים בזמן אימונו. זהו המנגנון העיקרי המאפשר למותגים להופיע בתוצאות החיפוש של AI באמצעות תוכן עדכני ומבוסס רשת.
15. Vector Database (מסד נתונים וקטורי)
מערכת אחסון המייצגת נתונים כווקטורים (נקודות) במרחב רב-ממדי, המאפשרת ביצוע חיפושי דמיון סמנטיים מהירים ומדויקים על פני מיליארדי רשומות. מסדי הנתונים הללו הם המרכיב הקריטי במערכות RAG מודרניות, שכן הם מאפשרים לשלוף מידע לפי משמעות ולא לפי מילות מפתח.
16. Embeddings (הטמעות)
ייצוגים מתמטיים של פיסות מידע (טקסט, תמונה וכו’) המקודדים את המשמעות הסמנטית וההקשר של המידע לתוך וקטור של מספרים. הטמעות הן השפה שבה מודלי AI “מבינים” את העולם, והן מאפשרות למדוד את המרחק הרעיוני בין שאילתת המשתמש לבין התוכן הקיים ברשת.
17. Tokens (טוקנים)
יחידות העיבוד הבסיסיות של מודלי שפה, שיכולות להיות מילים, חלקי מילים או סימני פיסוק, המשמשות לחישוב ההסתברויות והקשרים בתוך המודל. אופטימיזציית טוקנים ב-GEO פירושה כתיבה שמקטינה את מספר הטוקנים הנדרש להבנת המסר, ובכך משפרת את יעילות העיבוד של המודל.
18. Attention Mechanism (מנגנון תשומת הלב)
רכיב מרכזי בארכיטקטורת ה-Transformer המאפשר למודל להעניק משקל שונה לחלקים שונים של רצף הקלט בעת עיבוד שאילתה, ובכך להבין איזה חלק מהטקסט הוא הקריטי ביותר להקשר. מנגנון זה מאפשר למודל לקשור בין מילים הרחוקות זו מזו במשפט ולהבין ניואנסים מורכבים.
19. Context Window (חלון הקשר)
המגבלה הטכנית של כמות הטקסט המקסימלית (בטוקנים) שהמודל יכול לעבד בו-זמנית בתוך שאילתה אחת או רצף שיחה אחד. עבור GEO, חשוב לוודא שהמידע המרכזי נמצא בטווח שהמודל מסוגל “לזכור” ולעבד בעת שהוא מגבש את התשובה הסופית.
20. HNSW (Hierarchical Navigable Small World)
אלגוריתם מתקדם לאינדוקס וקטורי המאפשר חיפוש מהיר במיוחד של השכנים הקרובים ביותר בתוך מסד נתונים וקטורי, באמצעות מבנה של גרפים היררכיים. זהו רכיב טכני המבטיח שמערכות AI Search יוכלו להחזיר תוצאות בזמן אמת גם כאשר הן סורקות מאגרים ענקיים.
21. ANN (Approximate Nearest Neighbor)
טכניקת חיפוש וקטורית המאפשרת למצוא תוצאות קרובות מאוד לשאילתה בזמן קצר, תוך הקרבת מידה מזערית של דיוק לטובת ביצועים וסקלאביליות. ב-GEO, ההבנה שהחיפוש הוא “מקורב” מחייבת את יוצרי התוכן להיות ברורים וחד-משמעיים ככל הניתן בתיאור ישויות ומושגים.
22. Sharding (ביזור נתונים)
תהליך של חלוקת מסד הנתונים הווקטורי למספר יחידות קטנות יותר (Shards) שיכולות להיות מעובדות במקביל, מה שמאפשר למערכות AI search לטפל בכמויות דאטה עצומות. ביזור נכון מבטיח שהמערכת תישאר מהירה וזמינה גם כאשר נפח המידע המאוחזר גדל משמעותית.
23. Hallucinations (הזיות)
תקלה בפלט של מודל שפה שבה הוא מייצר מידע שגוי, לא קיים או מטעה שנראה משכנע מבחינה לשונית, לעיתים בשל מחסור במידע עדכני או הקשר נכון. מטרת ה-GEO היא לספק למודל “עיגון” (Grounding) חזק במציאות דרך מקורות מהימנים כדי לצמצם תופעה זו.
24. Prompt Engineering (הנדסת פרומפטים)
הפרקטיקה של ניסוח ובניית שאילתות מדויקות כדי להוציא מהמודל את התוצאה המיטבית, המשמשת ב-GEO גם לבדיקת הנראות של מותג בסימולציות שונות של חיפוש. אנשי מקצוע משתמשים בפרומפטים כדי להבין אילו מקורות המודל מעדיף ולבצע אופטימיזציה בהתאם.
פרק ג’: מדדי ביצוע (KPIs) וכלכלת הציטוטים
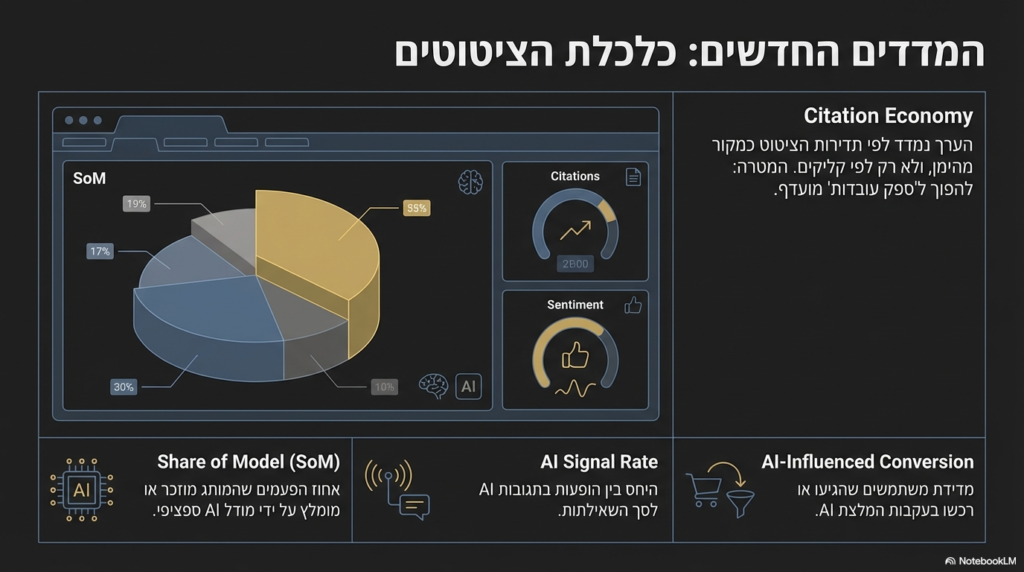
25. Citation Economy (כלכלת הציטוטים)
מבנה שוק דיגיטלי חדש שבו הערך והסמכות של מותג נמדדים לפי תדירות הציטוט שלו כמקור מהימן בתוך תשובות בינה מלאכותית, ולא רק לפי כמות הקליקים לאתר. במציאות זו, השפעה נבנית דרך הפיכה ל”ספק עובדות” מועדף על המודלים הגדולים.
26. Share of Model (SoM/ נתח מודל)
מדד ביצוע מרכזי המודד את אחוז הפעמים שמותג מסוים מוזכר, מצוטט או מומלץ על ידי מודל AI ספציפי בתגובה לשאילתות רלוונטיות בתעשייה שלו. זהו התחליף המודרני ל-Share of Voice, המאפשר להבין את רמת הדומיננטיות של המותג בתוך ה”קופסה השחורה”.
27. Position-Adjusted Word Count (ספירת מילים מותאמת מיקום)
מדד מחקרי המעריך את הנראות של מקור בתוך תשובה ג’נרטיבית על ידי שקלול מספר המילים המוקדשות למקור והמיקום שלהן (תעדוף לתחילת התשובה). מדד זה עוזר לכמת את ה”אימפרשן” האמיתי שהמשתמש מקבל מהמותג בתוך הטקסט המסונתז.
28. AI Signal Rate (שיעור סיגנל AI)
היחס בין מספר הפעמים שמותג מופיע בתגובות AI לבין סך השאילתות שנשאלו באותה קטגוריה, המשמש כאינדיקטור בסיסי לנוכחות המותג ב-LLMs. שיעור סיגנל נמוך מצביע על כך שהמותג נחשב ל”בלתי נראה” עבור המערכות הג’נרטיביות.
29. Answer Accuracy Rate (שיעור דיוק התשובה)
מדד הבודק את מידת הנכונות של המידע שה-AI מציג לגבי המותג בהשוואה למקורות האמת הרשמיים, תוך זיהוי הזיות או טעויות ייחוס. שמירה על שיעור דיוק גבוה (מעל 85%) היא קריטית לניהול מוניטין בעידין ה-AI.
30. AI-Influenced Conversion Rate (שיעור המרה מושפע AI)
אחוז המשתמשים שביצעו פעולה רצויה (רכישה, ליד) לאחר שקיימו אינטראקציה עם מנוע חיפוש ג’נרטיבי שהפנה אותם למותג או המליץ עליו. מדד זה מקשר את אסטרטגיית ה-GEO ישירות לתוצאות העסקיות ול-ROI.
31. Entity Recognition Accuracy (דיוק זיהוי ישויות)
המידה שבה מודל ה-AI מזהה נכון את המותג, מוצריו ואנשי המפתח שלו כישויות ייחודיות ונפרדות ממתחרים או ממושגים כלליים בעלי שם דומה. חוסר דיוק בזיהוי עלול להוביל לכך שהמודל יייחס תכונות חיוביות של המותג שלכם למתחרה.
32. Trust Depth (עומק אמון)
מדד הבוחן את סוג השאילתות בהן המותג מצוטט – האם רק בשאלות ידע כלליות (Top-of-funnel) או גם בשאילתות מורכבות של השוואה וקבלת החלטות (Bottom-of-funnel). עומק אמון גבוה מעיד על כך שהמודל תופס את המותג כסמכות אמינה לפתרון בעיות.
33. Zero-Click Impact Score (ציון השפעת “אפס קליקים”)
הערכת הערך המותגי והכלכלי שנוצר כתוצאה מהופעה בתשובות AI גם כאשר המשתמש לא מקליק לאתר, המבוססת על מדדי חשיפה, סנטימנט וזכירת מותג. בעידן שבו רוב השאילתות נענות ישירות, מדד זה הופך לקריטי להערכת הצלחת השיווק.
34. Brand Canon (קנון המותג)
בסיס נתונים רשמי ומאומת המכיל את כל העובדות והנתונים המדויקים על המותג, המשמש כנקודת ייחוס (Ground Truth) לבדיקת דיוק התשובות שמספקים מודלי ה-AI. ניהול קנון המותג מבטיח שהבינה המלאכותית תקבל נתונים עקביים מכל קצוות הרשת.
35. Consensus Factor (גורם הקונצנזוס)
המידה שבה מידע מסוים מופיע באופן עקבי במספר רב של מקורות חיצוניים ובלתי תלויים, מה שמעלה את רמת הביטחון של המודל בנכונות המידע ובסיכוי לצטט אותו. יצירת קונצנזוס סביב נתוני המותג (למשל דרך Reddit, חדשות ופורומים) היא כלי GEO עוצמתי.
36. Mention Sentiment (סנטימנט האזכור)
ניתוח אוטומטי של הטון וההקשר בהם מוזכר המותג בתוך תשובות ה-AI, המלמד על התפיסה של המודל כלפי איכות המותג ושירותיו. סנטימנט חיובי עקבי מעודד את המודל להמליץ על המותג בשאילתות עתידיות של “מה הכי טוב”.
פרק ד’: חוויית חיפוש וסמכות דיגיטלית
37. AI Overviews / SGE (Search Generative Experience)
התכונה המרכזית של גוגל המציגה סיכומים מבוססי AI בראש דף התוצאות, המשלבים מידע ממקורות שונים וקישורים ישירים לאתרים המצוטטים. הופעה ב-AI Overviews דורשת שילוב של SEO מסורתי חזק יחד עם אופטימיזציית תוכן למודלי השפה של גוגל (Gemini).
38. Conversational Search (חיפוש דיאלוגי)
שיטת אינטראקציה שבה המשתמש שואל שאלות בשפה טבעית וממשיך את השיחה עם המנוע על בסיס הקשר קודם, בדומה לשיחה עם בן אדם. אופטימיזציה לסוג זה של חיפוש מחייבת כתיבה שעונה על שאלות “למה” ו”איך” ולא רק ממוקדת במילות מפתח.
39. Intent Optimization (אופטימיזציית כוונות)
התהליך של התאמת התוכן לכוונת המשתמש העמוקה (מידע, רכישה, השוואה) ולא רק למילים הספציפיות שנכתבו בשאילתה. מנועי AI מזהים כוונות בצורה טובה בהרבה ממנועים מסורתיים, ולכן התוכן חייב לספק פתרון מדויק לצורך המשתמש.
40. Knowledge Graphs (גרפי ידע)
מבני נתונים המארגנים מידע על ישויות והקשרים ביניהן, המשמשים את מנועי החיפוש כדי לספק תשובות עובדתיות מהירות והקשר סמנטי עמוק. נוכחות חזקה בגרף הידע היא תנאי הכרחי לכך שה-AI יציג את המותג כמקור סמכותי ומוכר.
41. E-E-A-T (Expertise, Experience, Authoritativeness, Trustworthiness)
ארבעת עמודי התווך של גוגל להערכת איכות תוכן, שהפכו לקריטיים עוד יותר בעידן ה-GEO כמסננת המפרידה בין תוכן AI דל למידע אמין ומוסמך. מודלים ג’נרטיביים מתוכנתים להיות “שונאי סיכון” ולהעדיף מקורות המציגים הוכחות חותכות לניסיון ומומחיות.
42. Featured Snippets (קטעים נבחרים)
תיבות המידע המופיעות בראש תוצאות גוגל ומספקות תשובה ישירה, המשמשות לעיתים קרובות כבסיס שעליו נבנות התשובות הג’נרטיביות של המנוע. השגת “מיקום אפס” ב-Snippets היא אינדיקציה חזקה לכך שהתוכן שלכם מותאם ל-AEO ול-GEO.
43. LSI Keywords (מילות מפתח באינדוקס סמנטי לטנטי)
ביטויים ומילים הקשורים סמנטית לנושא המרכזי, העוזרים למודלי ה-AI למפות את המאמר בתוך “שכונה וקטורית” רלוונטית וסמכותית. שימוש ב-LSI מעיד על עומק הידע בתוכן ומונע זיהוי שלו כשטחי או דל.
44. Schema Markup (JSON-LD)
פורמט של נתונים מובנים המאפשר ליוצרי אתרים לתקשר ישירות עם מנועי חיפוש ו-AI לגבי משמעות הנתונים בדף (מוצרים, אירועים, שאלות נפוצות). שימוש נכון ב-Schema מעלה דרמטית את סיכויי הציטוט כיוון שהוא מוריד את הנטל של עיבוד השפה מהמודל.
45. AI Crawler (סורק AI)
בוט ייעודי המשמש חברות בינה מלאכותית (כמו GPTBot או PerplexityBot) לסריקת הרשת ואיסוף נתונים לאימון מודלים או לאחזור מידע בזמן אמת. ניהול נכון של גישת הבוטים הללו הוא חלק בלתי נפרד מאסטרטגיית ה-GEO הטכנית.
46. Information Gain (רווח מידע)
הערך המוסף והייחודיות של המידע בדף מסוים ביחס למה שכבר קיים באינדקס או בנתוני האימון של המודל. מנועי חיפוש ג’נרטיביים מעדיפים לצטט מקורות המביאים עמדה חדשה, נתון מקורי או ניתוח ייחודי שאינו סתם חזרה על דברים קיימים.
47. Entity Clarity (בהירות ישויות)
המידה שבה המותג מוגדר ומתואר ברחבי הרשת באופן עקבי שמאפשר למודלי AI לזהות אותו ללא עמימות. בהירות מושגת דרך אימות חשבונות, פרופילים עסקיים ואזכורים סמכותיים המקשרים את שם המותג לתחום פעילותו.
48. Agentic RAG (RAGסוכנותי)
גרסה מתקדמת של RAG שבה עוזר ה-AI מסוגל לבצע תכנון מורכב, להפעיל כלים חיצוניים (כמו APIs) ולקבל החלטות כדי להשלים משימות עבור המשתמש. עבור GEO, זה אומר שהתוכן צריך להיות מובנה כך שסוכני AI יוכלו “לפעול” עליו (למשל, להזמין תור או להשוות מפרט טכני).
49. Retrieval vs. Synthesis (אחזור מול סינתזה)
ההבחנה המקצועית בין המודל הישן של הצגת קישורים (אחזור) למודל החדש של יצירת תשובה מאוחדת ממקורות רבים (סינתזה). הבנה זו מחייבת מעבר מאופטימיזציה של “קליקים” לאופטימיזציה של “נוכחות בנרטיב”.
50. Subjective Impression (רושם סובייקטיבי)
מדד הערכה מחקרי שבו בוחנים אנושיים או מודלים בודקים את האיכות הכללית, הרהיטות והתועלת של תשובת ה-AI ביחס למקורות המידע ששימשו אותה. ציון גבוה ברושם סובייקטיבי מעיד על כך שהמקור תרם לא רק עובדות אלא גם מבנה וקוהרנטיות לתשובה.
GEO מעבר למונחים
חיפוש ג’נרטיבי הוא לא עוד שכבה של SEO, הוא שינוי באופן שבו מידע נצרך, מסונתז ומיוצג.
המושגים שפירטנו כאן הם לא טרנד רגעי, הם השפה של מערכת חיפוש חדשה שמבוססת על תשובות, הקשר וסמכות. מי שעובד בדיגיטל היום צריך להבין
לא רק איך להיות מדורג, אלא איך להופיע בתוך נרטיב שמודלים של בינה מלאכותית בונים בזמן אמת.
ב – Alt אנחנו חוקרים את הנושא הזה באופן שוטף. בודקים נראות במודלים שונים, מודדים אזכורים, ומתרגמים את המילון הזה לאסטרטגיית תוכן פרקטית. אם יש לכם שאלות לגבי איך המותג שלכם מיוצג בתוך תשובות AI שווה לבדוק את זה עכשיו, לפני שזה הופך לברירת מחדל.
צרו איתנו קשר ונשמח לסייע לכם בבדיקות ובקידום האתר במנועי החיפוש השונים.